AI建表助手
AI建表助手通过自然语言对话、文档解析与变量识别能力,帮助用户完成数据库表结构的规划、确认与创建。无论是创建用于存储海量实时数据的时序历史库,还是用于业务流转归档的关系型数据表,AI 都会先理解需求、匹配相关变量、生成建表方案,再通过对��话和卡片引导用户确认后执行,降低手动配置字段、公式、触发规则和底层数据库参数的成本。
功能说明
- 自然语言与附件解析:支持通过自然语言直接描述建表需求,或上传包含表结构、归档规则、统计口径等内容的
.csv、.txt等附件。AI 会从文本或附件中提取关键信息。 - 变量识别与字段生成:AI 会先读取工程变量树中的变量信息,并根据用户描述匹配相关变量。除基础数据表等不依赖变量的场景外,AI 会将字段、公式、聚合项、归档对象等与变量建立对应关系。
- 按业务场景生成方案:AI助手支持历史库和数据管理中的建表需求:
- 历史库归档配置:面向连续采集的时序变量,帮助用户匹配可归档变量,按变量类型和用户要求自动分组,推荐归档策略和参数,并生成历史组方案。
- 数据管理建表:面向业务归档、数据聚合和基础数据维护,帮助用户判断表类型,生成字段、触发规则、公式、关联关系等配置方案。
- 对话式确认与补全:在解析过程中,若 AI 发现需求不完整、变量范围不明确、归档策略缺失、字段类型未定义、关联关系不清楚等情况,会通过对话或卡片继续提问,引导用户补充信息。
- 方案确认与安全执行:在正式写入数据库前,AI 会生成完整的建表或归档方案供用户核对。用户可以继续提出修改意见,确认无误后再执行写入,确保底层数据结构安全可控。
核心优势
AI建表助手的价值不是替用户直接跳过确认,而是把复杂的建表配置过程拆成可理解、可校验的对话流程:
- 降低归档配置成本:把逐个查找变量、人工判断分组、手动选择归档策略和批量绑定变量的重复工作,收敛为可确认的方案生成过程,减少配置耗时,也降低新手误选"定时记录"、"变化记录"或填错死区、采集间隔的风险。
- 降低建表门槛:用户不必先掌握变量归档表、数据聚合表、基础数据表等表类型差异,也不必手动配置
PREVALUE、CHANGE等字段公式或聚合方式。AI 会根据需求判断需要的表结构与配置项。 - 减少变量匹配成本:AI 会结合工程变量树识别相关变量,避免用户在大量设备、产线和变量中逐个查找和绑定。
- 减少配置错误:对于数据聚合表的数据源、字段公式、触发规则、历史库归档策略等容易出错的关联关系,AI 会先生成结构化方案,再让用户确认。
- 支持渐进修改:如果方案不符合预期,用户可以继续通过对话调整变量范围、字段、公式、归档策略或触发条件,AI 会在原方案基础上重新生成确认结果。
典型使用场景
场景一:基于自然语言的历史库批量归档
背景:需要把二号产线的温度、压力、转速等实时变量存入历史库,以便后续生成趋势曲线。手动配置时,需要先创建历史组,再从变量树中逐个找到变量并绑定,还要判断哪些变量应使用同一套归档策略。 AI方式:
- 在 历史库 模块打开 AI 助手,输入:"把二号产线所有温度变量做历史归档,用变化记录。"
- AI 从工程变量树中匹配二号产线相关的温度变量,并根据变量类型和用户要求自动分组。
- AI 为每个历史组推荐归档策略和参数,例如变化记录、死区、采集间隔等。
- 如果变量范围或参数不明确,AI 通过卡片或对话继续询问。
- 工程师确认归档方案后,系统创建历史组并批量绑定变量。 价值:降低历史库配置门槛,减少逐个查找变量、人工分组和手动设置归档策略的重复劳动。
场景二:基于自然语言的班次能耗统计表创建
背景:能源管理人员希望按班次统计二号产线的用电量、用水量和压缩空气消耗,用于后续能耗分析和报表展示。 AI方式:
- 在 数据管理 模块打开 AI 助手,直接输入:"帮我建一个二号产线班次能耗统计表,按早班、中班、晚班分别记录用电量、用水量和压缩空气消耗。"
- AI 理解业务意图,判断适合创建数据聚合表,并从工程变量树中匹配二号产线相关的电表、水表和气耗变量。
- AI 生成包含统计字段、变量来源、班次时间范围、聚合方式和触发规则的建表方案。
- 工程师核对方案卡片,如需调整可继续对话修改;确认无误后点击执行。 价值:无需手动查找变量、配置聚合字段和班次触发规则,通过对话即可完成能耗统计表方案设计与创建。
5分钟快速上手
步骤1:选择入口并输入需求
根据您的数据类型(时序连续数据选"历史库",业务归档数据选"数据管理"),进入对应模块并打开 AI 助手对话框。
您可以直接输入文本描述建表需求,也可以将 .csv、.txt 格式的字段清单或归档规则作为附件发送给 AI。
历史库变量助手入口:
数据管理变量助手入口:
步骤2:AI 理解需求并匹配变量
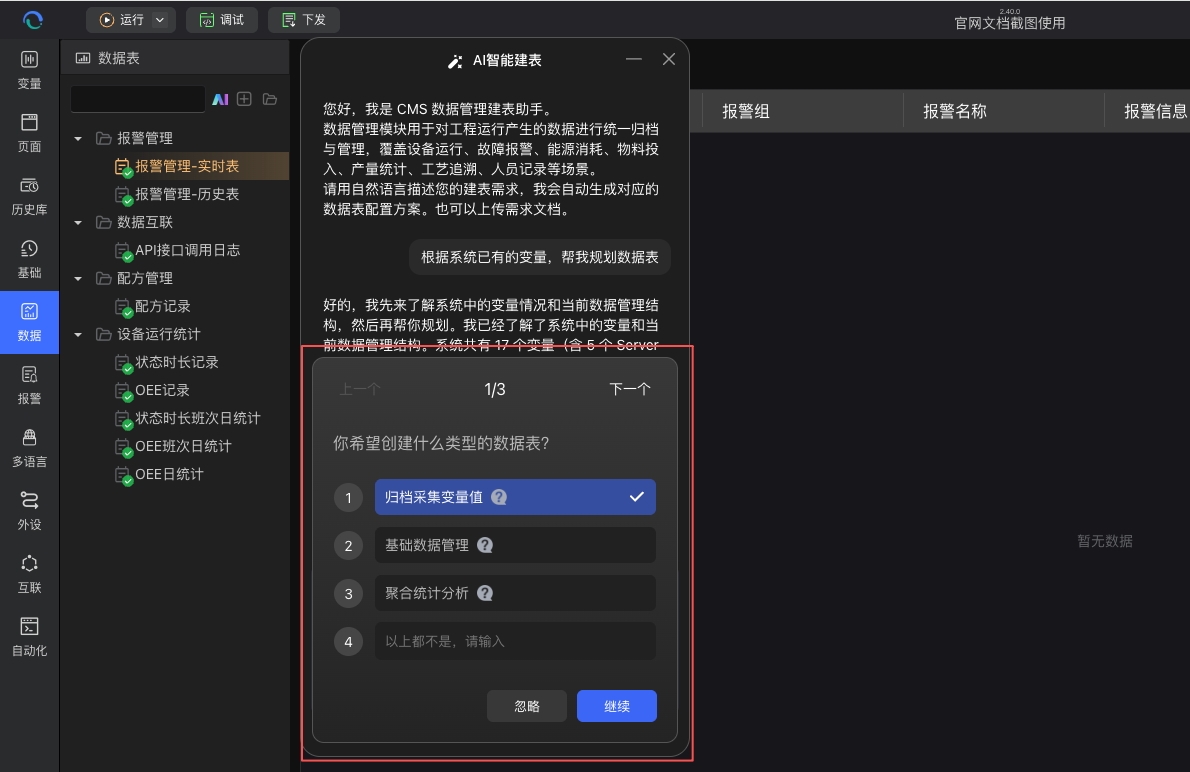
AI 接收到消息后,会自动解析文件或文本中的业务意图、表名、字段信息、触发条件、归档策略等内容,并读取工程变量树,匹配可能相关的变量。 如果发现必填项缺失(例如变量范围不明确、未指定数据类型、缺少主键、归档参数不完整、关联关系不清楚等),AI 会在对话流中发送一张补充信息卡片或继续追问。
步骤3:补充信息并提交
您只需根据卡片提示补齐信息,例如确认字段类型、设置采集间隔或死区、补充触发条件、确认数据源表等,然后点击提交。
步骤4:确认建表方案
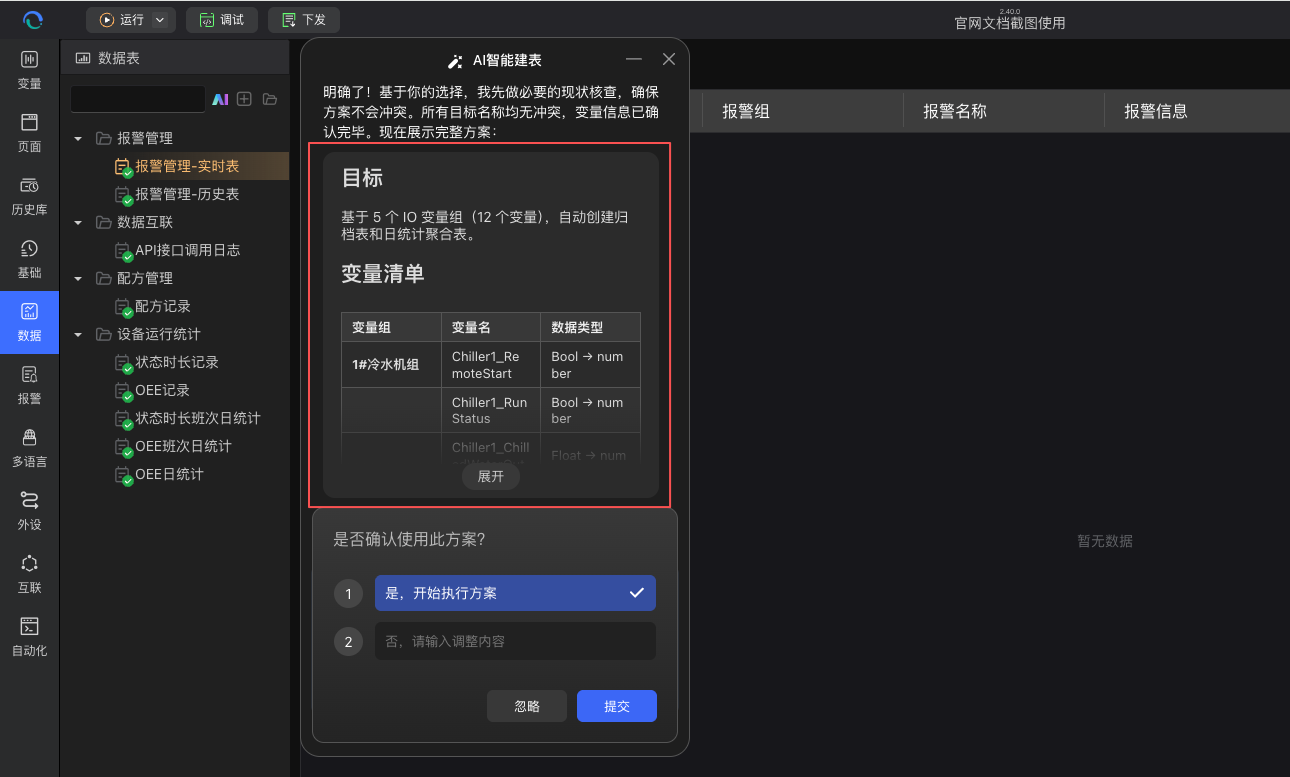
所有信息补全后,AI 会生成一份清晰的确认方案,展示即将创建的表名称、字段清单、变量来源、字段类型、触发规则、公式、关联关系或归档策略等内容。您可以核对方案是否符合预期,也可以继续通过对话要求 AI 调整。
步骤5:执行写入与查看结果
点击方案卡片上的"确认并执行",AI 会自动在后台执行数据库建表操作。完成后,您可以直接在当前模块的数据表列表中查看已成功创建的表格。
提问与操作技巧
技巧一:明确数据类型以减少提问
如果您希望减少 AI 的追问,可以在首次对话或附件中明确各字段的类型、变量范围、触发条件或归档策略。例如:"建一个订单表,包含 订单号(String)、金额(Float)、创建时间(DateTime)。" AI 会优先据此生成确认方案。
技巧二:对话式的渐进修改
如果在方案确认阶段发现字段遗漏,无需重新上传附件。直接对 AI 说:"再帮我加一个'操作员'字段,类型是文本",AI 会自动在原方案基础上追加字段并让您重新确认。
常见问题
Q1: 目前支持哪些格式的文件上传?
A: 目前支持标准化文本表格文件,如 .csv 和 .txt。如果您的字段规划在 Excel (.xlsx) 中,建议先另存为 CSV 格式后再上传。
Q2: 在历史库和数据管理的建表有什么不同?
A: 两者的交互流程相似,都会先理解需求、匹配变量、生成方案,并在用户确认后执行。区别在于配置重点不同:历史库主要用于时序数据归档,更关注变量范围、历史组分组、采集间隔、死区、定时记录或变化记录等参数;数据管理主要用于业务数据表或聚合表,更关注表类型、字段、触发规则、公式、数据源和关联关系。您无需手动处理底层差异,只需按卡片提示确认即可。
Q3: AI 建的表可以修改吗?
A: 可以。AI 建表完成后,该表与手动创建的表在系统中没有任何区别。您依然可以通过系统的图形化界面对表结构进行增删改查。
最佳实践
1. 将复杂需求拆分为文档上传
如果是只包含三五个字段的小表,直接用一句话描述最快。但如果字段超过十个,建议先在 Excel 中把 字段名 和 数据类型 列好,导出 CSV 上传给 AI,这样准确率最高,也便于自己核对。
2. 结合变量助手使用
在搭建监控系统时,通常的流程是:先用 AI变量助手 将设备点表接入系统,形成可识别的工程变量树,然后再使用 AI建表助手 匹配这些变量并生成历史库或数据管理建表方案,实现数据的"采、存、用"闭环。