历史库概述
1.概述
1.1应用场景
工业现场的各种设备、传感器产生大量实时数据,包括温度、压力、流量、电流等各种参数,这些数据以高速率产生,需要有效的存储和管理。
历史库功能模块,使用"标签化存储"的数据存储结构,这种存储结构能够有效地存储和管理海量的历史数据,提供高效的数据检索和查询功能。标签化存储结构将所有数据存储在一个大的数据表中,并对每个数据点进行标记,这样就能够轻松地检索和查询所有数据点。此外,标签化存储结构还支持多种数据类型和数据格式,包括数字信号、模拟信号、事件信号等,能够满足各种历史数据管理需求。
同时,历史库还使用了一些高级的时序数据库技术,如压缩算法、索引技术、数据分区技术等。这些技术能够提高数据存储和查询的效率,同时保证数据的可靠性和连续性。
1.2功能对比
| 历史库 | 数据管理 | |
|---|---|---|
| 存储类型 | 时序型数据 | 关系型数据 |
| 功能定位 | 专门用于时序数据存储和管理的功能。主要目的是持久化存储大量实时产生的工厂现场数据,并提供数据记录、存储、查询功能。 | 一种数据管理和归档方法,通过触发器机制将指定的数据提供给数据表进行存储。 |
| 核心功能点 | 核心功能包括高性能的数据存储和检索,支持实时数据采集、存储和查询,提供数据预压缩和按照时间窗口进行聚合的功能。 | 在特定条件下触发数据的归档操作,将数据提供给归档系统进行存储,包括根据时间、事件、数据状态等条件进行触发。 |
| 解决痛点 | 主要解决了工厂需要存储大量实时产生的时序数据,并对数据进行高效管理和查询的问题。它可以帮助用户记录历史数据、识别趋势和模式,支持决策制定和问题解决。 | 主要满足将特定数据按需归档的场景。用户根据自定义规则和条件,将重要或特定的数据提供给数据表进行长期存储,以便后续的数据分析等。 |
1.3功能介绍
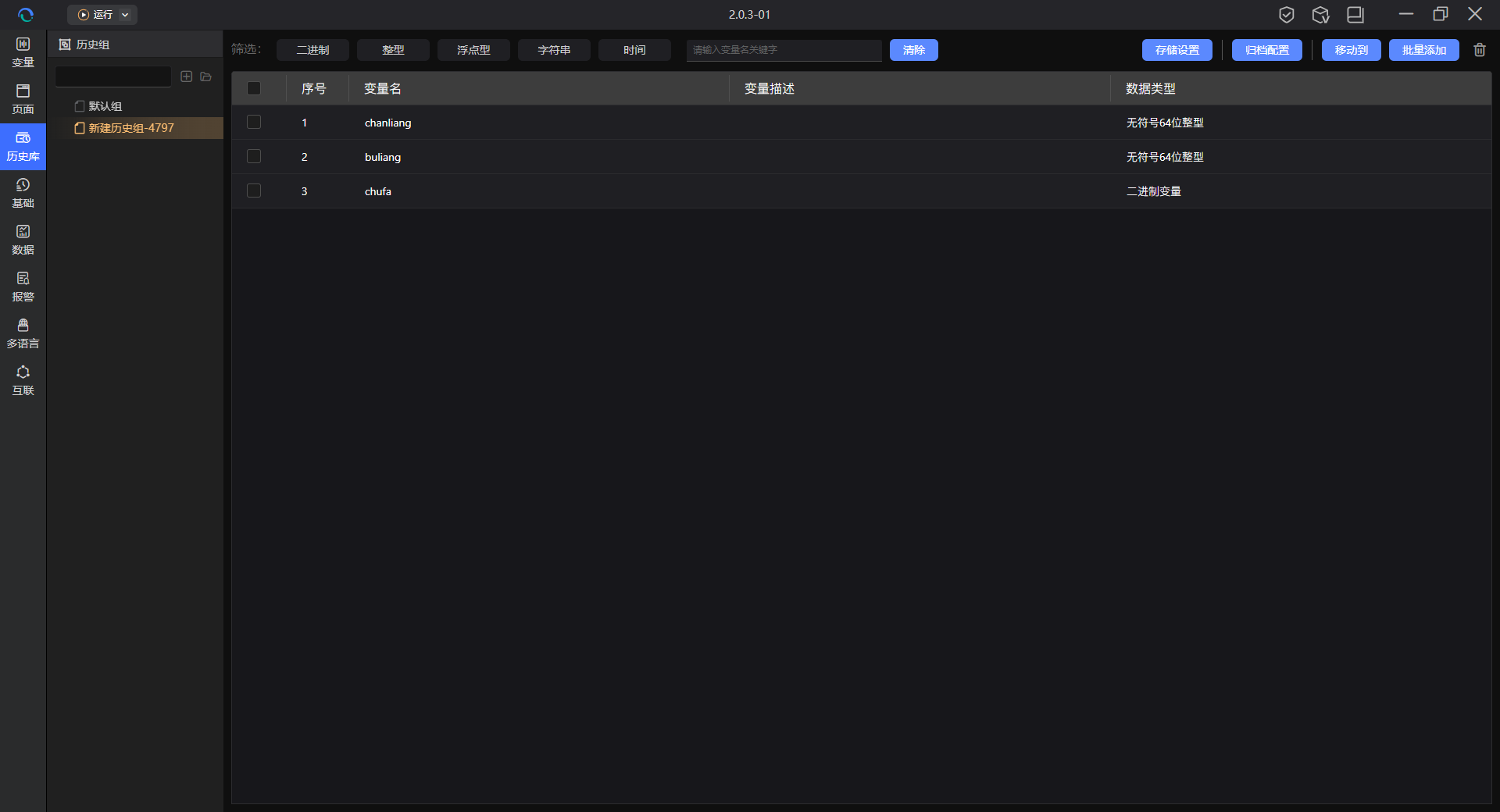
整体说明
变量的历史归档配置,可在变量管理模块,历史归档列进行分别设置,也可在历史库模块,以历史组的方式进行统一设置。历史归档配置默认不启用,需要手动进行设置。
注:分别设置的变量,自动归属于默认组,默认组不具备统一设置功能。
**历史组:**用于以分组的形式,对相同归档规则的变量进行统一管理,并提供以下功能;
-
批量添加:可添加多个变量进当前历史组,历史组的配置统一应用在这些变量上;
-
移动到:可批量调整当前历史组的变量,移动到另一历史组内;
注:一个变量,只能归属于一个历史组,历史组执行添加或移动变量的时候,变量自动归属于新的历史组;
-
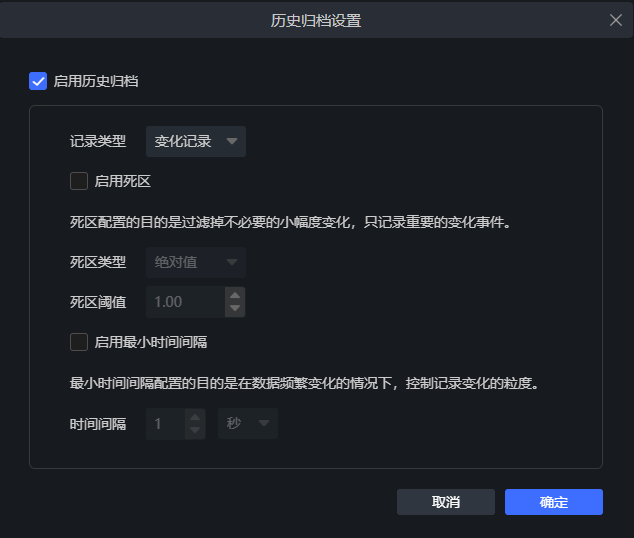
归档配置:
-
定时记录:用于现场数据采集的周期性归档,关注数据基于固定时间间隔的变化趋势;

-
变化记录:用于现场数据采集的关键变化数据归档,关注数据在关键时间节点的变化结果;
-
死区:启用死区后,变量每次变化的幅度,要大于阈值才会被记录,阈值指变量当前采集值和上一次有效记录值的正负偏差,实际死区区间会自动变化;
注:死区只对整型、浮点型的变量数据才生效;
- 绝对值:固定的阈值,提前设置;
-
百分比:动态的阈值,根据变量当前采集值和上一次有效记录值的正负偏差比率自动生效;
-
最小时间间隔:启用最小时间间隔后,变量每次变化时,距离上次变化要大于最小时间间隔才会被记录;
-
-
-
数据备份:将当前历史组已归档的数据进行全部导出,用于工程重要存储数据的手动备份及查看;
-
数据清除:将当前历史组已归档的数据进行全部清除,用于工程调试过程中及部署前的旧数据清除;
-
删除:删除当前历史组配置,原属于历史组的变量,自动转为未启用历史归档配置,相当于批量取消变量的历史归档配置;